Twitter系サービス怒濤のリリース第4弾。 Twitter上でつぶやかれたURLを収集し、人気順に並べるサービス「Twib(ツイブ!)」 を昨晩より公開しました。 はてな風味ということもありサブタイトルは「Twitter ホットエントリー」となっております。
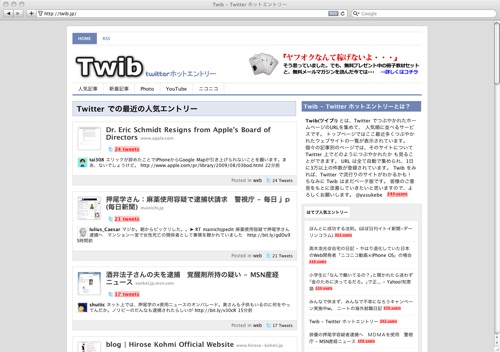
現在の仕様では、トップページにおいて ここ12時間以内で新たにでてきたサイトから、そのURLをつぶやいたユーザーが多い順に並べて表示しています。 また、新着記事は3時間以内、カテゴリー別で「Photo」「YouTube」「ニコニコ動画」という具合に フィルターをかけて人気記事を見ていくこともできます。
各々の個別ページでは、そのURLについてどのようにみんながつぶやいているかを見ることができるので、 いろいろな意見が知れて面白いです。
「ちょw、これはてブでいいんじゃねw」
って感じかもしれませんがw、実際ここ1日動かしてみて、上位にランクインされる記事を見ると、 はてなブックマークとは違う傾向がわかってきました。 今のところその差を言葉ではうまく表すのは難しいのですが、 Twib の方が例えば技術記事などは少なく、どちらかというと庶民的な雰囲気がしますね。 ということで、現在は「押尾学逮捕」の記事満載であります。
さて徐々に仕組みの話に入っていきます。 収集対象となるURLを含んだポストは1日で約3万件にのぼります。 重複を考慮すると実際は2万件程度でしょうか。 そこそこ多くのサンプルから人気記事を算出していることになります。 では、そのURLを含んだTwitterのポストとはいったいどこまでの範囲かと言いますと、 「日本語のつぶやき全て」を範囲としています。
これらのリソースを収集し、整理する点がこのTwibにとってコアの仕組みとなっています。 簡単に紹介してみましょう。 まず、「日本語のつぶやき かつ URLを含んだ」Twitterのポストをどのように拾ってくるかですが、 Twitterオフィシャルの検索サイトからあるキーワードで日本語指定をして、検索。 その結果がフィードどして取得できるためそれを利用しています。 cron で動かすようなフェッチャを作ってもよかったのですが、 今回は AnyEvent::Feed という CPAN モジュールを使ってプログラムを常駐させ、 30秒に一度フィードのエントリーを取得するという方法をとっています。 AnyEvent::Feed は POD にも書いてありますが、一定のインターバルで新しくでてきたエントリを 取得するのに重宝しますね。
It also keeps track of already fetched entries so that you will only get the new entries.
AnyEvent::Feed - Receiving RSS/Atom Feed reader with XML::Feed - search.cpan.org
この AnyEvent::Feed を含んだ FeedReader によって逐一ポストの情報が DB に入る仕組みになっています。 以下が、ちょい汚いけど実際に使っているソースの該当部分です。
sub run {
my $self = shift;
my $cv = AnyEvent->condvar;
my $feed_reader = AnyEvent::Feed->new(
url => $self->url,
interval => $self->interval,
on_fetch => sub {
my ( $feed_reader, $entries, $feed, $error ) = @_;
if ( defined $error ) {
warn "ERROR: $error\n";
$cv->send;
return;
}
for (@$entries) {
my $entry = Twib::CLI::Feed::Entry->new( $_->[1] );
if( my $post = $self->create_post( $entry ) ){
}
}
}
);
$cv->recv;
}
さて、収集する部分の他にもう一つ整理するプログラムが必要になってきます。 これは完全なクローラーです。 Twitter の言及に含まれるURLは短縮サービスによって縮められることが多いので、 それを展開するためにリクエストをおくりつつ、また、記事のタイトルやサマリーを取得するために クロールしています。 つまり FeedReader が登録したポストでまだ未チェックのものに対して一定時間間隔で、 URL についての解析を行うわけです。 この部分は、本来なら非同期処理のできる Coro::LWP や AnyEvent::HTTP などを使いたいと思う、 というか非同期じゃないと間に合わない可能性があるのですが、 DB との連携がうまくいかない等動かない現状にあるので単純な LWP を最適化したプログラムでまかなっています。
これら「収集プログラム」、「URL解析整理プログラム」の2つがTwibのコアとなります。 上記した通り、収集プログラムは30秒毎、解析整理プログラムは数分おきの実行となるため、 ほぼリアルタイムに近くサイト上へ反映されることになりますね。
以上、Twib 公開のお知らせと、仕組みについて簡単に説明してきました。 まだチェックしてない方は是非みてみてください。 というわけで Enjoy!